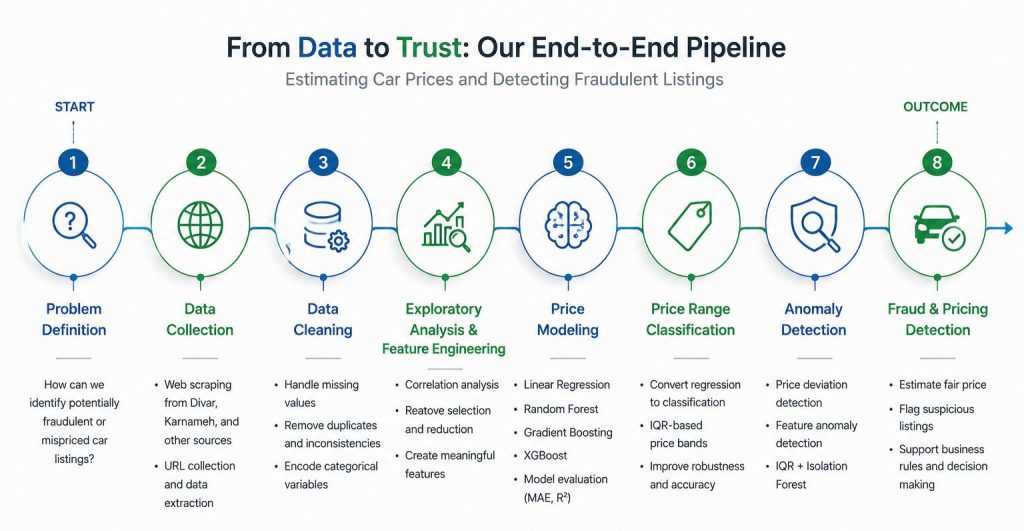
How can we identify potentially fraudulent or mispriced vehicles in online marketplaces?
The first step was building a pricing model capable of estimating a vehicle’s market value based on its characteristics. Features such as the manufacturing year, mileage, color, body condition, and other listing attributes were used to predict each vehicle’s expected price.
Rather than relying on a single algorithm, we evaluated several machine learning approaches, ranging from traditional statistical models to more advanced ensemble methods. Linear Regression served as a baseline, while Random Forest, Gradient Boosting, and XGBoost were used to capture more complex relationships within the data.
Interestingly, the results challenged some common assumptions.
Model | MAER²
Linear Regression ~46.2 Million | 0.867
Random Forest ~44.1 Million | 0.855
Gradient Boosting ~47.0 Million | 0.833
XGBoost ~47.1 Million | 0.838
Despite being the simplest model in the experiment, Linear Regression achieved the highest coefficient of determination (R²), while Random Forest produced the lowest prediction error (MAE). This suggests that vehicle prices in our dataset are driven largely by a few dominant factors—particularly manufacturing year and mileage—resulting in a relationship that is more linear than expected.
The most interesting part, however, was not predicting prices. It was using those predictions to identify suspicious listings.
We approached this problem from two different perspectives.
The first was price-based detection. If the listed price deviated significantly from the model’s estimated value, the vehicle was flagged for further inspection. This approach is straightforward, interpretable, and easy to integrate into business workflows.
The second was feature-based anomaly detection. Instead of focusing on price, we examined the vehicle’s characteristics. By combining statistical outlier detection techniques such as the Interquartile Range (IQR) with machine learning methods like Isolation Forest, we were able to identify listings whose attributes appeared unusual compared to the rest of the market.
This distinction is important. A listing may have a reasonable price while still containing suspicious or inconsistent information. Likewise, a vehicle may appear normal but be significantly overpriced or underpriced relative to its expected market value.
By combining price estimation with anomaly detection, the final pipeline goes beyond answering the question “What is this car worth?” and begins addressing a more valuable one:
“Does this listing look trustworthy?”
The result is a system capable of estimating market prices while simultaneously highlighting potentially fraudulent, mispriced, or unusual listings—providing a practical tool for marketplace monitoring and business rule enforcement.
Leave a Reply