Have you ever wondered how second-hand car prices are estimated?
Two years ago, while searching for my first car, I spent months browsing online marketplaces and visiting dealerships. At some point, I realized I could estimate the price of most vehicles with surprising accuracy.
Yet, if someone asked me how I arrived at those numbers, I couldn’t fully explain it. The process felt almost intuitive—similar to how a neural network reaches a conclusion without explicitly describing every intermediate step.
That experience stayed with me and eventually led to a question:
Can we build a system that learns this pricing intuition and explains the relationship between a car’s characteristics and its market value?
Living in a relatively small city such as Yazd turned out to be an advantage. It made it easier to gather local market information and construct a dataset that reflected real-world pricing behavior.
Although platforms such as Divar and Karnameh previously offered vehicle price estimation services, these systems eventually disappeared. While I do not know the exact reasons, factors such as rapid inflation, frequent market fluctuations, and operational challenges may have made maintaining accurate models increasingly difficult.
Our objective was to develop a model that could learn quickly, remain reliable under changing market conditions, and capture the relationship between vehicle attributes and price.
The first challenge became clear very early in the project: predicting an exact price through regression alone resulted in a large prediction error (MAE). In practice, the market is too noisy for precise price estimation.
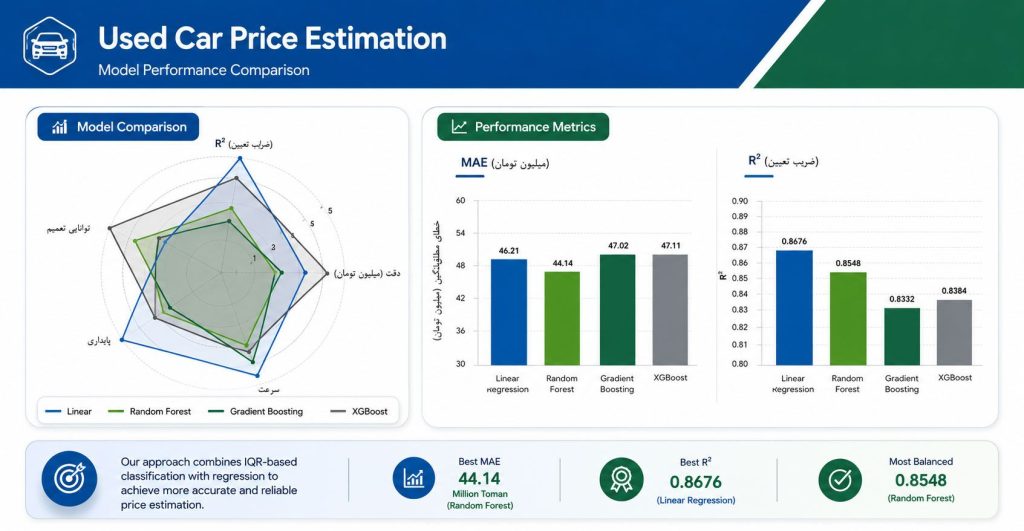
To address this, we reformulated the problem. Instead of directly predicting an exact price, we transformed the task into a classification problem. Vehicle prices were grouped into intervals of approximately 20 million Tomans, with class boundaries refined using the Interquartile Range (IQR). Once the model identified the appropriate price range, we combined this information with regression techniques to obtain more accurate final estimates.
The project involved more than a month of data collection from online marketplaces—a process that was far from straightforward due to unstable servers, request timeouts, and inconsistent responses. After cleaning the data, we experimented with multiple machine learning algorithms and used correlation analysis to reduce input dimensionality and remove less informative variables.
The final results confirmed our initial hypothesis: combining IQR-based classification with regression produced significantly more reliable price estimates than relying on regression alone.
The figures below summarize some of the results and model performance.
In the coming weeks, I will share more details about the dataset, data collection pipeline, feature engineering process, model selection, and the final research article once everything is ready.
Leave a Reply